AI Art Weekly #134
Hello, my fellow dreamers, and welcome to issue #134 of AI Art Weekly! 👋
I’m currently working on my next music video, which will consist of 383 unique scenes (I’m insane, yes). Now, I could create these scenes all by myself, but it’s always more fun to involve the community in a project like this. So if you have a spare minute, please consider submitting an image to this thread 🙏
Currently, 10% of all scenes are community submissions, but the video would be even more amazing if as many people as possible would contribute an image or two 🤗
Support the newsletter and unlock the full potential of AI-generated art with my curated collection of 375+ high-quality Midjourney SREF codes and 4000+ creative prompts.

News & Papers
Highlights
- Moondream released Moondream 3 Preview, a new tiny SOTA object detection model with powerful visual reasoning.
- Alibaba released Qwen-Image-Edit-2509, an improved Qwen-Image-Edit model that supports multi-image editing with ControlNet support.
- Google released Mixboard, a canvas based ideation tool with generative AI capabilities (basically dingboard.com).
- Robots are still getting the shit kicked out of them, what could possibly go wrong 😅
3D
Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self-Distillation
Lyra can generate 3D scenes from a single image or video. It uses a method that allows real-time rendering and dynamic scene generation without needing multiple views for training.

Lyra example
MeshMosaic: Scaling Artist Mesh Generation via Local-to-Global Assembly
MeshMosaic can generate high-resolution 3D meshes with over 100,000 triangles. It breaks shapes into smaller patches for better detail and accuracy, outperforming other methods that usually handle only 8,000 faces.

MeshMosaic example
Video
CapStARE: Capsule-based Spatiotemporal Architecture for Robust and Efficient Gaze Estimation
CapStARE can achieve high accuracy in gaze estimation. It works in real-time at about 8ms per frame and handles extreme head poses well, making it ideal for interactive systems.

CapStARE example
Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Wan-Animate can animate characters from images by copying their expressions and movements from a video. It also allows for seamless character replacement in videos, keeping the original lighting and color tone for a consistent look.

Wan-Animate example
SynchroRaMa : Lip-Synchronized and Emotion-Aware Talking Face Generation via Multi-Modal Emotion Embedding
SynchroRaMa can generate lip-synchronized talking face videos that show emotions. It uses audio-to-motion for natural head movements and provides high image quality and realistic motion, as shown in user studies.

SynchroRaMa
example
OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models
OmniInsert can insert subjects from any video or image into original scenes without masks. It solves problems like data scarcity and subject-scene balance, achieving better results than other methods.

OmniInsert example
Stable Video-Driven Portraits
Stable Video-Driven Portraits can generate high-quality, photo-realistic videos from a single image by reenacting expressions and poses from a driving video.

Stable Video-Driven Portraits example
Audio
AudioLBM: Audio Super-Resolution with Latent Bridge Models
Audio Super-Resolution with Latent Bridge Models can upscale low-resolution audio to high-resolution, achieving top quality for 48kHz and setting a record for 192kHz audio.
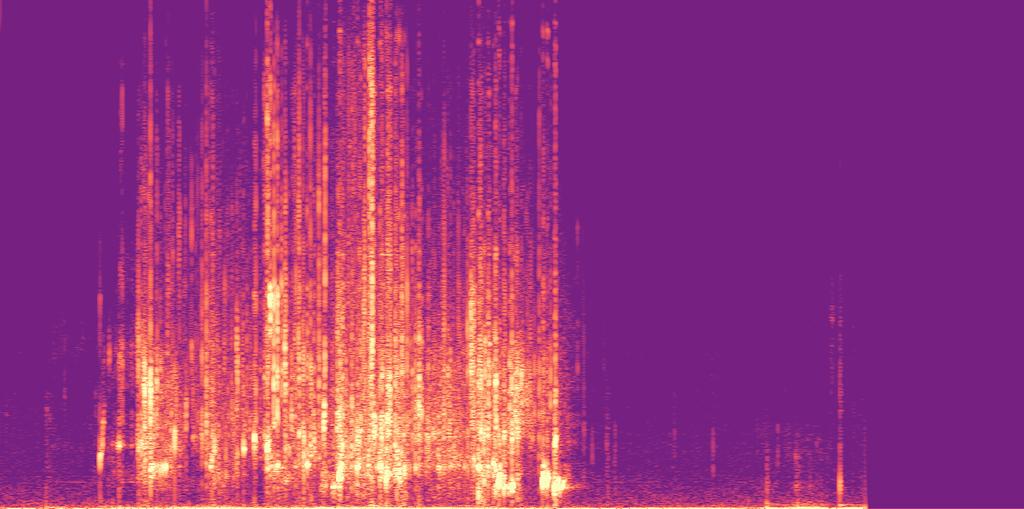
Upscaled Spectogram created by AudioLBM
STAR: Speech-to-Audio Generation via Representation Learning
STAR can generate audio from speech input while capturing important sounds and scene details.
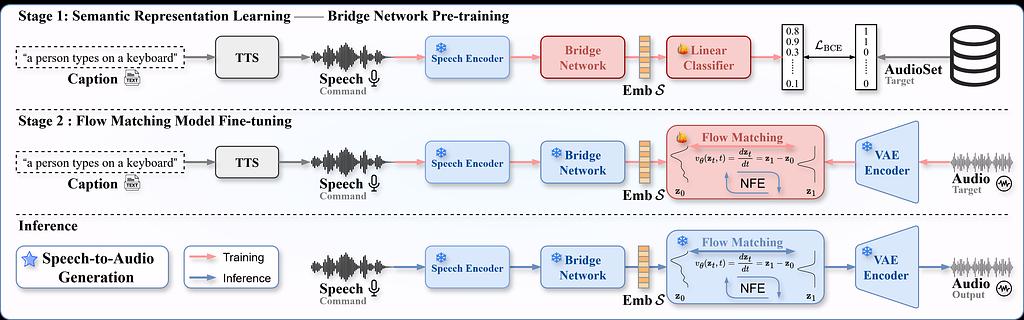
An overview of STAR framework and training strategy
Beyond Video-to-SFX: Video to Audio Synthesis with Environmentally Aware Speech
Beyond Video-to-SFX can generate synchronized audio with clear speech from videos.

Beyond Video-to-SFX example. Check the project page for audio.

these violent thoughts have violent delights --chaos 100 --ar 4:3 --exp 100 --raw --stylize 1000 --weird 1000 --p
And that my fellow dreamers, concludes yet another AI Art weekly issue. If you like what I do, you can support me by:
- Sharing it 🙏❤️
- Following me on Twitter: @dreamingtulpa
- Buying me a coffee (I could seriously use it, putting these issues together takes me 8-12 hours every Friday 😅)
- Buying my Midjourney prompt collection on PROMPTCACHE 🚀
- Buying access to AI Art Weekly Premium 👑
Reply to this email if you have any feedback or ideas for this newsletter.
Thanks for reading and talk to you next week!
– dreamingtulpa